ЗтУцаТЮХМЧепOuyang Hongyuгк4дТ29ШеЩЯЮчЃЌАЂРяАЭАЭПЊЩшСЫThyi Qianwen Model Qwen3ЕФаТвЛДњЃЈГЦЮЊQianwen3ЃЉЁЃИљОн
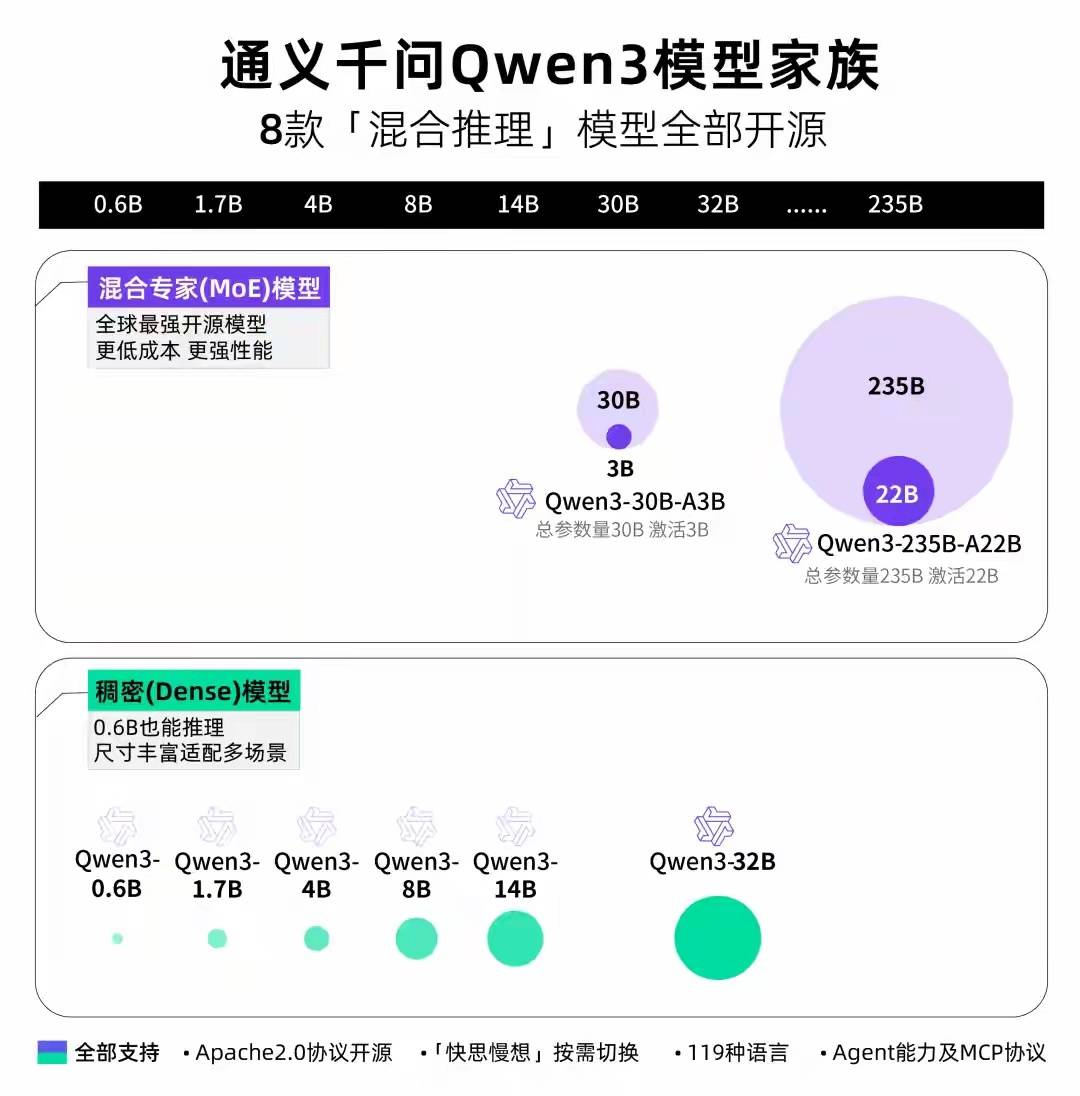 ЗтУцаТЮХМЧепOuyang Hongyuгк4дТ29ШеЩЯЮчЃЌАЂРяАЭАЭПЊЩшСЫThyi Qianwen Model Qwen3ЕФаТвЛДњЃЈГЦЮЊQianwen3ЃЉЁЃОнБЈЕРЃЌИУДѓаЭДѓаЭФЃаЭЕФВЮЪ§Ъ§СПНіЮЊDeepSeek-R1ЕФ1/3ЃЌВЂЧвГЩБОЯдзХЯТНЕЃЌЦфадФмГЌЙ§R1ЃЌOpenAI-O1ЕШЁЃЙЋЙВаХЯЂБэУїЃЌQianwen3ЪЧжаЙњЕФЕквЛИіЁАЛьКЯЭЦРэФЃаЭЁБЁЃ ЁАПьЫйЫМПМЁБКЭЁАЛКТ§ЫМПМЁББЛећКЯЕНЭЌвЛФЃаЭжаЃЌДгЖјДѓДѓНкЪЁСЫМЦЫуЧПЖШЕФЯћКФЁЃОнСЫНтЃЌQianwen3ВЩгУСЫЛьКЯзЈМвЃЈMOEЃЉЕФЬхЯЕНсЙЙЃЌзмВЮЪ§ЮЊ235bЃЌНіашвЊ22BВХФмМЄЛюЃЌВЂЧвдЄЯШХрбЕЕФЪ§ОнСПДяЕНСЫ36TСюХЦЁЃдкбЕСЗКѓНзЖЮНјааСЫаэЖрЧПЛЏбаОПжЎКѓЃЌИУФЃаЭВЂЮДШЯЮЊЮоашМЏГЩЕНЫМЮЌФЃаЭжаЁЃетдкЭЦРэЃЌзёЪиНЬбЇКЭЙЄОпЗНУцИпЖШдіЧПКєНаЃЌЖргябдЙІФмЕШЁЃЕБЧАЃЌQianwen 3ФЃаЭАцБОАќРЈ230BКЭ235B MOEаЭКХЃЌвдМА6жжУмМЏаЭаЭКХЃЌАќРЈ0.6BЃЌ1.7BЃЌ4BЃЌ4BЃЌ8BЃЌ14BКЭ32BЁЃжЕЕУзЂвтЕФЪЧЃЌЫцзХадФмЕФИФЩЦЃЌРЉДѓQianwen 3ЕФГЩБОвВДѓДѓЯТНЕЁЃжЛФмЪЙгУ4 H20РДВПЪ№Qianwen 3ШЋбљАцБОЃЌЖјЪгЦЕМЧвфЯћКФНіЮЊОпгаЯрЫЦадФмЕФФЃаЭЕФШ§ЗжжЎвЛЁЃ
ЗтУцаТЮХМЧепOuyang Hongyuгк4дТ29ШеЩЯЮчЃЌАЂРяАЭАЭПЊЩшСЫThyi Qianwen Model Qwen3ЕФаТвЛДњЃЈГЦЮЊQianwen3ЃЉЁЃОнБЈЕРЃЌИУДѓаЭДѓаЭФЃаЭЕФВЮЪ§Ъ§СПНіЮЊDeepSeek-R1ЕФ1/3ЃЌВЂЧвГЩБОЯдзХЯТНЕЃЌЦфадФмГЌЙ§R1ЃЌOpenAI-O1ЕШЁЃЙЋЙВаХЯЂБэУїЃЌQianwen3ЪЧжаЙњЕФЕквЛИіЁАЛьКЯЭЦРэФЃаЭЁБЁЃ ЁАПьЫйЫМПМЁБКЭЁАЛКТ§ЫМПМЁББЛећКЯЕНЭЌвЛФЃаЭжаЃЌДгЖјДѓДѓНкЪЁСЫМЦЫуЧПЖШЕФЯћКФЁЃОнСЫНтЃЌQianwen3ВЩгУСЫЛьКЯзЈМвЃЈMOEЃЉЕФЬхЯЕНсЙЙЃЌзмВЮЪ§ЮЊ235bЃЌНіашвЊ22BВХФмМЄЛюЃЌВЂЧвдЄЯШХрбЕЕФЪ§ОнСПДяЕНСЫ36TСюХЦЁЃдкбЕСЗКѓНзЖЮНјааСЫаэЖрЧПЛЏбаОПжЎКѓЃЌИУФЃаЭВЂЮДШЯЮЊЮоашМЏГЩЕНЫМЮЌФЃаЭжаЁЃетдкЭЦРэЃЌзёЪиНЬбЇКЭЙЄОпЗНУцИпЖШдіЧПКєНаЃЌЖргябдЙІФмЕШЁЃЕБЧАЃЌQianwen 3ФЃаЭАцБОАќРЈ230BКЭ235B MOEаЭКХЃЌвдМА6жжУмМЏаЭаЭКХЃЌАќРЈ0.6BЃЌ1.7BЃЌ4BЃЌ4BЃЌ8BЃЌ14BКЭ32BЁЃжЕЕУзЂвтЕФЪЧЃЌЫцзХадФмЕФИФЩЦЃЌРЉДѓQianwen 3ЕФГЩБОвВДѓДѓЯТНЕЁЃжЛФмЪЙгУ4 H20РДВПЪ№Qianwen 3ШЋбљАцБОЃЌЖјЪгЦЕМЧвфЯћКФНіЮЊОпгаЯрЫЦадФмЕФФЃаЭЕФШ§ЗжжЎвЛЁЃ